Novas aplicações web e sites com diferentes finalidades são criados a todo instante nos dias atuais, diversas ferramentas que antes eram hospedadas em servidores locais estão deixando este ambiente de lado e migrando para soluções web ou em nuvem devido à redução de custos. A questão é: Como e onde hospeda-los? Para isso existem empresas que disponibilizam recursos, espaço em seus servidores ou data centers e conexão à internet, oferecendo um serviço dedicado que propõe segurança dos dados e alta disponibilidade.
Novas aplicações web e sites com diferentes finalidades são criados a todo instante nos dias atuais, diversas ferramentas que antes eram hospedadas em servidores locais estão deixando este ambiente de lado e migrando para soluções web ou em nuvem devido à redução de custos. A questão é: Como e onde hospeda-los? Para isso existem empresas que disponibilizam recursos, espaço em seus servidores ou data centers e conexão à internet, oferecendo um serviço dedicado que propõe segurança dos dados e alta disponibilidade.
Lista de hostings para hospedagem de sites e aplicações web
Ao buscar um serviço de hosting para hospedagem de um site, devemos considerar alguns pontos relevantes quanto aos serviços oferecidos por empresas, dentre eles estão: espaço de armazenamento em disco, taxa de transferência, domínios, compatibilidade com sistemas operacionais, suporte ao cliente e preços.
A seguir será apresentado uma lista dos 10 serviços de hostings para hospedagem de sites, expondo informações como espaço disponível, limite de transferência, domínios, compatibilidade, preços e outras informações consideradas importantes:
HostGator: Oferece domínio único, 100GB de armazenamento, transferência ilimitada, contas de e-mail grátis e criador de sites, seu preço é de R$12,79/mês ou R$153,50/ano. Possui descontos na renovação, além de suporte ao usuário 24/7.
GoDaddy: Oferece um plano de R$23,99/mês com 100GB de armazenamento, transferência ilimitada, 1 conta de e-mail com 10GB de armazenamento e 1° ano de domínio grátis. Suporte ao usuário funciona de segunda a sexta via telefone.
UOL Host: Uol oferece em seu plano de hosting, um armazenamento de 10GB, transferência ilimitada, até 30 contas de e-mail com 12GB de armazenamento cada, 2 domínios e um construtor de sites por um valor de R$9,90/mês. O suporte ao usuário funciona 24/7 por e-mail, telefone e chat.
Locaweb: Armazenamento ilimitado, transferência ilimitada, 25 contas de e-mail com 10GB cada e criador de sites por R$17,90/mês no 1° ano depois passa a ser R$30,90/mês nos anos seguintes. Suporte ao usuário 24/7 via telefone e chat e oferece um 1 ano de domínio grátis.
DreamHost: Armazenamento ilimitado, transferência ilimitada, contas de e-mail ilimitadas com 2GB de armazenamento cada e 1 domínio por R$18,19/mês. Oferece suporte ao usuário 24/7 em inglês.
Kinghost: Armazenamento de 10GB, transferência ilimitada, contas de e-mail ilimitadas com um tamanho total de 50GB, criador de sites e serviço de proteção SSL por um valor de R$12,50/mês. Oferece bancos de dados em SSD e backup diário incluso nos planos. Suporte ao usuário funciona 24/7 através de chat, telefone e e-mail.
Bluehost: Armazenamento de 50GB, transferência ilimitada, até 5 contas de e-mail com até 100MB de armazenamento cada, criador de sites e 1 domínio por R$12,50/mês. Oferece suporte ao usuário 24/7 em inglês e CloudFlare pronto para utilização.
Inmotion hosting: Armazenamento ilimitado, transferência ilimitada, contas de e-mail ilimitadas com armazenamento ilimitado, 2 domínios, criador de sites e compatibilidade com diversas linguagens de programação por R$18,92/mês. A empresa oferece armazenamento em disco SSD e backup gratuito, além de um atendimento ao usuário que funciona 24/7 em inglês.
Digital Ocean: Armazenamento de 20GB SSD, 1TB de transferência, contas de e-mail conforme solicitado pelo contratante com acréscimo no valor padrão. O valor mínimo dos planos é de R$15,00/mês, mas a empresa permite que o contratante possa aumentar o armazenamento em disco por aproximadamente R$30,00 cada 100GB de armazenamento SSD. O serviço é oferecido através de servidores virtuais (VPS). O serviço de suporte oferecido é em inglês através de tickets.
Media Temple: Armazenamento de 20GB SSD, 1TB de transferência, até 1000 contas de e-mail, permite até 100 sites e compatibilidade com diversos bancos de dados por um valor de R$63,00/mês. Suporte ao usuário oferecido funciona 24/7 através de e-mail, chat, telefone e twitter, apenas em inglês. Também está incluso backup diário automático.
Há uma infinidade de serviços disponíveis por empresas, cada um deles com especificações e ofertas diferentes que podem atender diversos tipos de aplicações. Para isso é necessário que usuário saiba avaliar a necessidade de recursos que sua aplicação ou site irá precisar. Nesta lista foram apresentados os planos mais simples disponíveis pelas empresas selecionadas, porém cada uma das empresas citas oferecem planos mais robustos oferecendo uma maior quantidade de recursos.
Autor: Adriano Saldanha de Oliveira
Links relacionados:
https://tudosobrehospedagemdesites.com.br/ranking-melhor-hospedagem-de-sites/
https://tudosobrehospedagemdesites.com.br/hospedagem-de-sites/











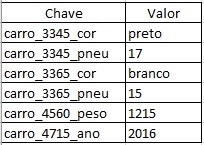
 Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.
Algumas definições importantes que devem ser apresentadas de um banco de dados relacional, como sua interface de comunicação o SQL, a sua integridade de dados, ou seja, a forma em que os bancos mantem sua precisão e consistência de dados, assegurada principalmente pelo seu sistema de transações que garantem que “tudo ou nada” seja gravado.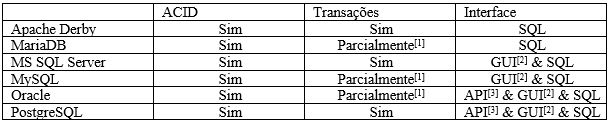
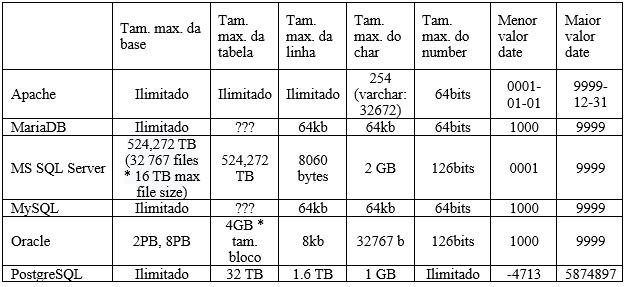
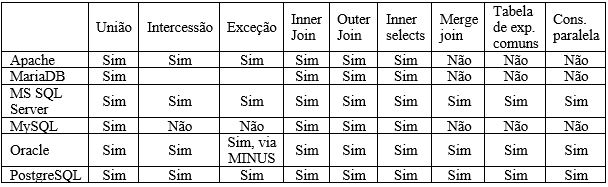



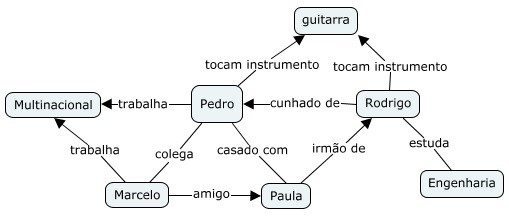
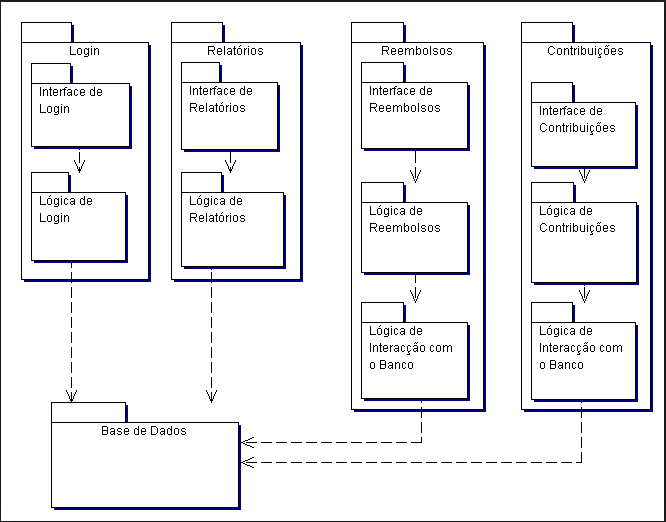
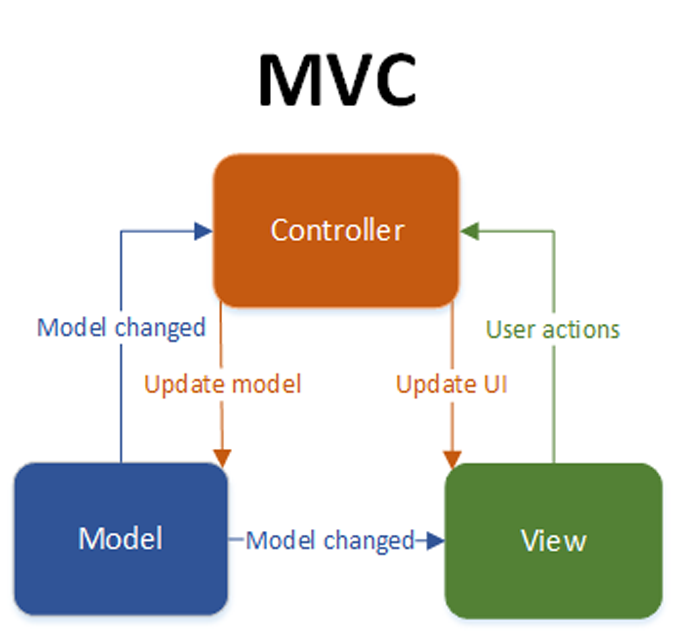 Figura 1: Objetos utilizados no MVC e suas interações.
Figura 1: Objetos utilizados no MVC e suas interações.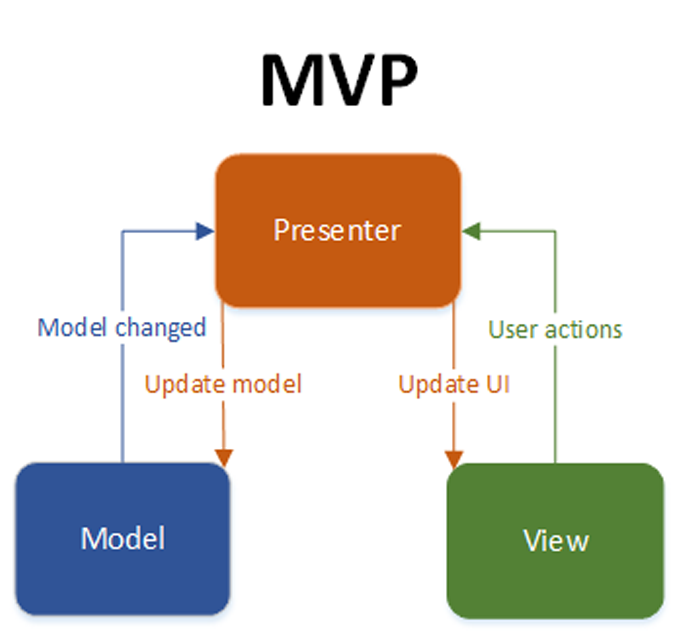


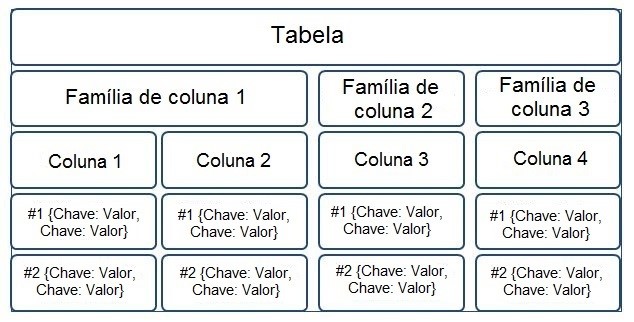
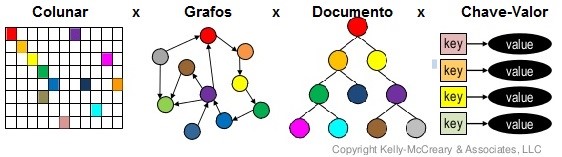 Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.
Os bancos de dados NoSQL não são todos iguais. Há grandes diferenças no que se refere como a forma de armazenamento e conceitos de modelagem. Basicamente se subdividem em técnicas de armazenamento diferentes. Há 4 tipos básicos de bancos de dados NoSQL, a seguir eles são descritos.