Sistemas inteligentes conseguem identificar falhas antes mesmo que elas causem impacto real
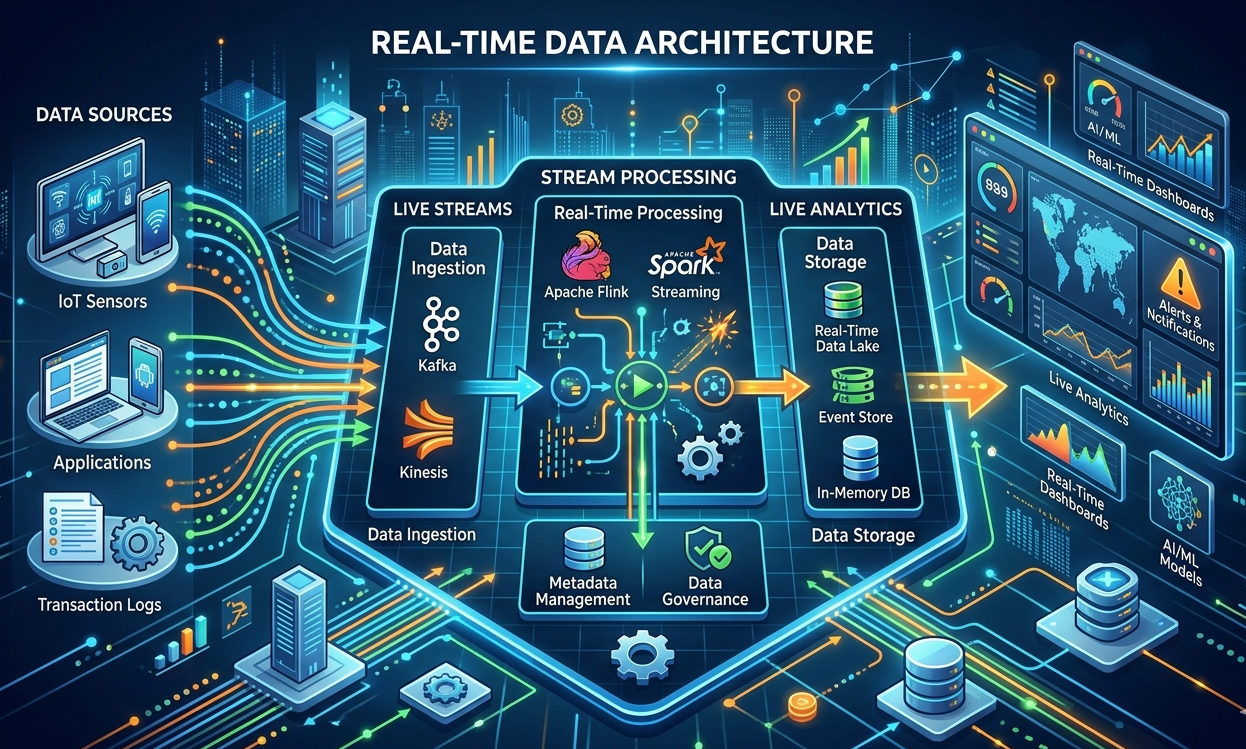
Com o crescimento da complexidade dos sistemas de software, tornou-se cada vez mais desafiador garantir seu funcionamento contínuo e seguro. Pequenas falhas podem gerar grandes impactos, como indisponibilidade de serviços, prejuízos financeiros e perda de dados. Nesse cenário, a detecção de anomalias e os alertas inteligentes surgem como soluções fundamentais para monitorar sistemas e identificar comportamentos fora do padrão.