
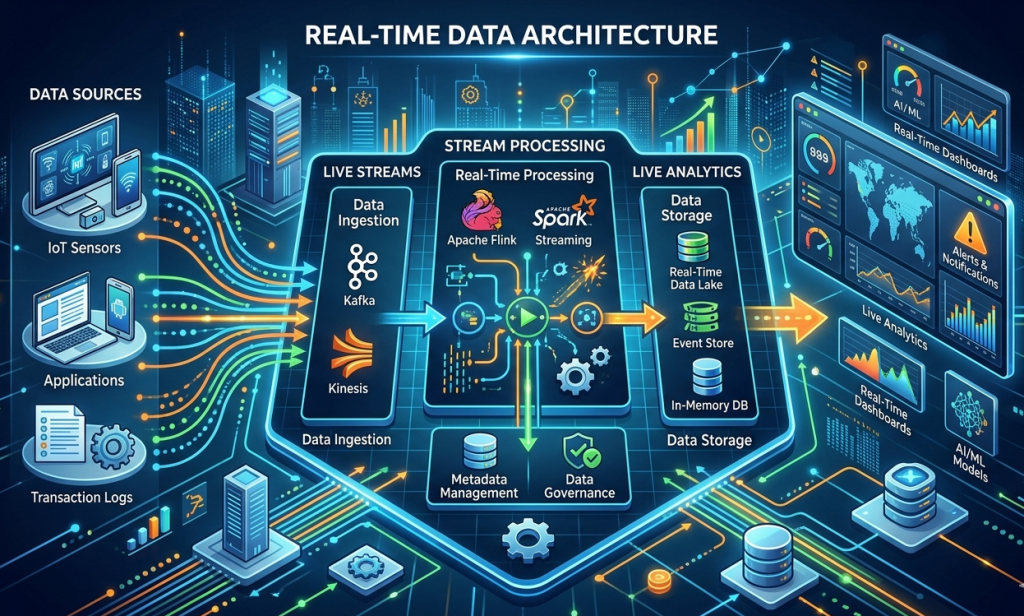
Introdução: O Problema de Negócio Antes da Tecnologia
Falar de arquitetura de dados costuma ser cansativo. Sinceramente, a coisa toda cansa. As equipes focam tanto nas ferramentas que a dor real da empresa simplesmente evapora. São discussões intermináveis sobre Kafka, Flink e Spark. Sem contar os debates teóricos tentando decidir qual modelo é melhor, Lambda ou Kappa. O jargão engole a prática. E no fim das contas qual é o saldo? A equipe gasta uma fortuna numa solução de prateleira sem nem saber qual problema está tentando resolver.
Para entender o desafio que é operar dados no milissegundo em que eles nascem, a gente precisa olhar pelo retrovisor. Durante muito tempo a nossa área tratou a informação como caixas empilhadas num galpão. A regra do jogo era acumular o máximo de caixas ao longo do dia. Depois a equipe arrumava tudo na madrugada. Clientes dormindo e servidores folgados. Esse é o velho e bom processamento em lote, o famoso batch. E sendo bem sincero aqui: ele funciona perfeitamente até hoje para um monte de coisas.
A Herança do Processamento em Lotes (Batch)
Na época de ouro dos mainframes e armazéns de dados, a madrugada era um horário sagrado. Imagina fechar o caixa de uma rede inteira de supermercados. Ou então rodar o arquivo de remessa de um banco. Fazer isso ao meio dia ou às três da manhã não muda absolutamente nada. A conta bate igual. Esse modelo traz uma previsibilidade enorme para quem cuida da infraestrutura. Tudo muito seguro e controlado. Se o script quebrar de noite, o plantonista vai lá e reinicia o servidor. De manhã cedo o relatório já está na tela da gerência.
O problema só começa quando o relógio dita quem tem lucro. A paciência do usuário de hoje em dia simplesmente acabou. Imagina um banco perceber que clonaram um cartão só doze horas depois do roubo. O criminoso já gastou tudo. A operadora vai ter que engolir o prejuízo calada. Pensa num site de ecommerce. Qual é a lógica de recomendar um tênis baseado no que o cliente olhou no mês passado se ele acabou de colocar outro sapato no carrinho agora mesmo? A janela para agir é mínima. O dado perde valor muito rápido.
Evolução Arquitetural: Do Caos da Lambda à Simplicidade da Kappa
Foi para resolver esse problema que o streaming ganhou força. O Twitter sentiu a pressão lá por 2011. Eles precisavam rastrear os assuntos do momento no exato instante da viralização. Só que recalcular o banco de dados inteiro a cada minuto derrubava qualquer máquina. A primeira saída foi a Arquitetura Lambda. Uma rota lenta para os dados antigos. E uma rota rápida para os dados novos. Lá na frente o sistema juntava tudo.
Elegante no papel. Um verdadeiro problema na hora de escrever o código. A equipe precisava programar a mesma regra de negócio duas vezes em tecnologias diferentes. Os resultados quase nunca batiam. Para resolver essa situação criaram a Arquitetura Kappa. A premissa dela é bem direta. Se a ferramenta é robusta o bastante para processar o fluxo contínuo sem descartar o histórico, não é preciso de duas rotas. Uma via única resolve o problema. Ocorreu alguma falha? Manda o sistema reler os eventos armazenados de novo.
O Ecossistema Tecnológico e a Centralidade do Log
Acompanhando esse movimento, o Apache Kafka dominou o mercado. Deixou de ser um simples intermediário de mensagens. Virou um registro blindado. Um log imutável que organiza os dados e deixa tudo pronto para acesso. Com essa estrutura no lugar, ferramentas de processamento pesado como o Apache Flink entram em cena. Elas cruzam informações e entregam os cálculos numa velocidade impressionante.
Mas colocar isso em produção de verdade é bem mais complicado do que parece. Os tutoriais da internet escondem os aspectos mais difíceis. Lidar com streaming na prática significa tratar dados chegando fora de ordem o tempo todo. A nuvem sempre oscila. Um usuário clica num botão enquanto passa por um túnel sem sinal. Essa ação vai chegar no servidor muito depois de um clique feito numa conexão rápida de fibra ótica. Se o sistema for cego para a diferença entre a hora em que o dado nasceu e a hora que o servidor recebeu o pacote, as métricas vão todas para o lixo.
Desafios de Produção: Estado e Observabilidade
Outro desafio sério é manter o contexto. Como o sistema sabe que dois eventos separados vieram do mesmo usuário no intervalo de meia hora? Ele precisa guardar isso na memória. O servidor reiniciou de forma inesperada? O histórico se perde. Sem uma engenharia cuidadosa salvando checkpoints com regularidade, o motor de recomendação perde toda a utilidade. E tem mais. Sem monitoramento constante a arquitetura vira uma caixa preta. É preciso saber em tempo real se quem consome os dados consegue ler na mesma velocidade com que o sistema produz.
Conclusão: Quando o Investimento se Justifica
No fim das contas, migrar para o mundo do tempo real não pode ser uma decisão baseada em tendência de mercado. O esforço e o dinheiro investidos só valem a pena se o atraso custar dinheiro de verdade para a empresa. Uma vitrine atualizada na hora e uma fraude bloqueada no ato justificam esse investimento. Para os demais casos, a orientação de quem já enfrentou problemas sérios em produção é clara. Comece pela via única. Sair adicionando componentes complexos e duplicando lógica sem ter um problema concreto pela frente é o caminho mais rápido para comprometer o projeto antes mesmo do lançamento.
Autor: Guilherme Chiele
Referências
KLEPPMANN, Martin. Designing Data Intensive Applications. Sebastopol: O’Reilly Media, 2017.
KREPS, Jay. Questioning the Lambda Architecture. O’Reilly Radar, 2014.
MARZ, Nathan; WARREN, James. Big Data: Principles and Best Practices of Scalable Realtime Data Systems. Manning Publications, 2015.
APACHE SOFTWARE FOUNDATION. Apache Kafka Documentation. Disponível em: https://kafka.apache.org/documentation/.
APACHE SOFTWARE FOUNDATION. Apache Flink Documentation. Disponível em: https://flink.apache.org/.
MICREIROS. IA aplicada a conhecer o perfil do usuário. Disponível em: https://micreiros.com.br/ia-aplicada-a-conhecer-o-perfil-do-usuario/.